
Masks Fail Their Latest Test
By Steve Kirsch
Masks do not work to protect anyone from SARS-CoV-2. It’s all based on sloppy science. We asked the senior author of the Bangladesh mask study to defend his study. He failed. Badly. Very badly.
Summary
The CDC just decided to continue the transportation mask mandate for another two weeks. Dr. Bob Wachter, Chair of the Department of Medicine at UCSF, concurs with the CDC decision. This doesn’t prove that masks work. Instead, it proves that the CDC, Wachter, and most mainstream scientists (who claim masks work) are incapable of differentiating solid science from a sloppy study.
There have been only two randomized trials to test whether public policy using masks to mitigate the spread of SARS-CoV-2 can reduce the spread.
The first one, in Denmark, failed to show that masks made a difference. However, they were forced to re-write their paper to claim masks worked in order to get their study published. This is known as “scientific corruption to match the political narrative.”
But the second one, in Bangladesh, claimed that masks worked.
Nature called it a “rigorous study” and Stanford and Yale promoted it as definitive in a press release.
But was it really? We challenged Yale Professor Jason Abaluck, the first author of that study, to defend their study. To his credit (and our utter amazement), he agreed but with one condition: we were only allowed one person to challenge him (because that’s how science works of course). We instantly agreed.
The discussion happened on April 3, 2022. The result: Abaluck failed. Badly. Very badly. One of our experts who viewed the interview said that it was worse than just sloppy work. He wrote, “This is bordering on fraud.”
In short, the Bangladesh mask study again failed to prove that masks make a difference. It was all statistical noise.
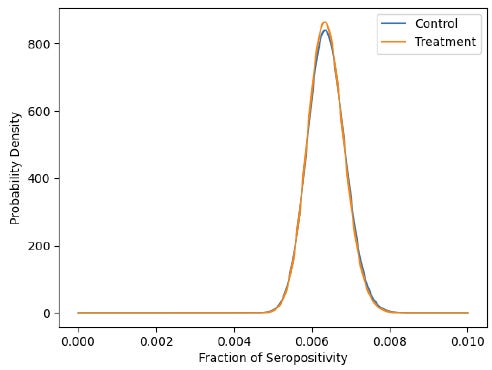
For example, here’s the graph for purple cloth masks. If masks worked, it would be highly unlikely for these curves to be on top of each other. For some strange reason, graphs such as these were omitted from the paper. Can you guess why??? Yes, it’s because the study was designed to fit the narrative. Subgroup analysis that goes against the narrative is not shown in the paper. That would cause people to ask questions.
You can see the entire 2-hour Abaluck discussion yourself and make your own judgment. You can watch Jason contract himself multiple times and make appeals to authority.
I also include a link to my interview with statistician Mike Deskevich on his interpretation of the Abaluck discussion. In the video, Mike clearly explains why the study shows no effect and he does it in just a few charts. You don’t need to know much about statistics to see what is going on. As soon as you see the huge variation in the control groups (and the huge variation based on mask color), it’s over. This is a great video because you’ll learn how to interpret other studies like this.
Initially, Professor Abaluck was so self-confident he thought he could run circles around us. He was wrong. The truth won.
So now Abaluck has changed his tune. He now says he won’t talk to us anymore or answer any more questions.
The bottom line is this: there is no rock on Earth that is large enough for study authors to hide under. The use of masks to slow the spread of SARS-CoV-2 has been debunked.
Masks don’t work. There is a reason these studies failed to find an effect: it’s because there is no measurable effect. Our team has said this from the beginning.
In fact, even Fauci agrees masks don’t work. Watch this video starting at 29 seconds into it where he admits it might make people feel better and it might block a “droplet or two.”
Science today is not about transparency. It is about finding creative ways to adjust your study to please your funders and then to avoid being challenged by hiding from people who seek to challenge your work. This is why I can’t get a debate on vaccine safety and efficacy with any of the members of the FDA or CDC committees, for example.
This interview with Abaluck shows that when we do get a chance to challenge mainstream beliefs, we win. So far, we’ve only been given a single “at bat” opportunity. We are now 1-0.
So now you know why we can’t find any authority who wants to debate our team on any of our points: they know they will lose. So they make up excuses to avoid being challenged like that we are misinformed, lack credentials, or that they don’t have time for such silliness as defending their study. This is also why there is such an intense focus on censoring, deplatforming, gaslighting, and discrediting us: because they don’t want their bad science to be exposed.
Introduction
As any of my readers can attest, I have been trying since May 25, 2021 to get anyone from the other side to challenge me and a few of my team members to discuss whether I am spreading misinformation or the truth.
Thus far, I have been unable to get anyone to take any of my offers, even with million dollar incentives. Here are some of my offers:
- Who wants to be a millionaire?
- “Name your price” offer to qualified vaccine proponents
- Earn $5K if you can find someone who is willing to publicly show us how we got it wrong
- My “name your price” offer to the members of the FDA and CDC outside committees)
- Can any company or government agency justify their own COVID mask policy?
So I was overjoyed recently when I finally got a qualified person willing to challenge on a recorded video our assertion that all public mask policies deploying cloth, surgical, and N95 masks are nonsensical and not justified by science.
Finally, for the very first time, the world will get to see a discussion between the two sides on a key issue: Do masks work?
The two randomized studies on masks and SARS-CoV-2
There have only been two randomized trials testing the hypothesis that masks can reduce the spread of COVID.
The first one, in Denmark, was negative. Masks made no difference. But in order to get the study published, they had to change the science to match the narrative. This was all well documented in the BMJ, one of the few honest journals left. I note that nobody disputes this.
The second one, in Bangladesh, claimed masks are effective. It is the study that all the “experts” seized upon. “See, masks work!!”
I asked the first author, Yale Economics Professor Jason Abaluck, if he would answer a few questions we all had on the study as none of us believed it. It was cluster randomized so it didn’t have sufficient power to detect a small signal. Plus, purple cloth masks showed no effect at all, red cloth masks were the most effective, and surgical masks were in between the two. This means it’s all statistical noise.
Lots of people had issues with the Bangladesh study
El gato malo and UC Berkeley Professor Ben Recht were two of the first people to point out the flaws in the Bangladesh mask study. Then our team independently verified Recht’s work. See Masks don’t work and skip down to the section entitled, “Supporting evidence that the Bangladesh study showed masks don’t work” for all the articles analyzing the study.
In other words, it was clear to the critical thinkers in the room that there was no detectable benefit at all.
But Professor Abaluck said that we got it wrong. And to our utter amazement, he agreed to defend his study in an interactive discussion.
We could not believe it!!!!
A first author who is willing to engage our team and defend his study!?!? That has never happened before. Never! Normally these people run for the hills when we call on them. Could we have made a mistake? We thought about it for a few seconds… nah, no way.
There was one big condition: Jason would only agree to engage with us one person at a time.
To make it a “fair” exchange, we picked someone on our team (James Lyons-Weiler) who was completely unfamiliar with the study and we gave him a week to read the study and prepare.
So the discussion is between:
- the person in the world who is arguably the most familiar with the study (Professor Abaluck) vs.
- one of our guys (James) who just read the study a week ago.
Guess what happened? Yeah. Professor Abaluck lost. Big time. You can watch the 2-hour video here or if you are short on time, just read all the comments.
It got even worse. When Professor Abaluck realized he was dealing with people who called his bluff, he basically said, “Stop with the questions!” If this isn’t a tacit admission that his study is deeply flawed, I don’t know what is.
Professor Abaluck basically doesn’t want to talk to us anymore because we ask hard questions and point out serious flaws in his study. And we caught him contradicting himself multiple times in this short 2-hour conversation. One of our experts from the UK (a very famous math professor) viewed the video and was appalled. He wrote to me, “This is bordering on fraud.”
If anyone with any serious academic credentials thinks the Bangladesh mask study and the video discussion proves that masks work, I’d be willing to pay you $100K to show us we got it wrong (you only get the money if you can convince any of our team members on the call).
Of course, nobody will take us up on the offer because they know every person we discredit like this just makes the case for masks even worse.
So even though there is no cost to get the $100K, the risk is you lose and discredit yourself and dig a deeper hole that makes it even harder for anyone to defend the study in the future. That’s why nobody qualified to defend the study will do so even though there is no financial risk; the reputational risk is huge.
The Mike Deskevich analysis of the Abaluck interview: highly recommended
Watch my interview with Mike.
It shows very clearly with just a few charts that the study is all noise and any signal is smaller than the noise.
You don’t need to be a statistician to be able to understand this.
Masks (cloth, surgical, and N95) do not work to protect you from getting COVID.
Masks can’t possibly work. This was very clearly explained by industrial hygienist Stephen Petty in his testimony for the New Hampshire Senate. Read the Description on the Rumble video of Petty’s testimony. It is excellent, one of the best descriptions available. Here’s an excerpt:
Face masks protect neither the wearer (self-protection) nor others (source control), because their pores are way too large to inhibit aerosols. It’s like trying to stop a mosquito with a tennis net. Also, masks leak, which further significantly reduces their already negligible protection.
Lastly, any droplets that are stopped by the mask initially will evaporate within a short period of time, because masks have no reservoir. It’s like putting an almost flat saucer under a leaking faucet. The saucer may stop water droplets initially, but will overflow very quickly.
Or consider this quote from Dr. Richard Urso:
“Masks have been looked at for three decades or so. There are twelve or so Randomized Control Trials (RCT’s). There are zero RCT’s that show masks stop the spread of respiratory disease and that’s including N95. For everyone, N stands for non-oil resistant and 95 stands for 95% airborne particles of which all viruses fit through. So, I usually tell people that wearing an N-95 has been shown through RCT’s to not be effective. But, more importantly the capsule on these viruses is an oil capsule and I tell people it’s like peeing in a pool. It goes right through and it doesn’t stick to water molecules, it’s an oil capsule virus. At the end of the day, the data is what it is. There is zero, repeat zero, RCT’s at all showing masks stop upper respiratory disease.”
If masks worked as claimed, then why do these studies on masks of various types fail?
- Surgical mask vs N95 respirator for preventing influenza among health care workers: a randomized trial which showed no difference between the mask types.
- Use of surgical face masks to reduce the incidence of the common cold among health care workers in Japan: a randomized controlled trial which showed surgical masks made no difference in preventing colds; but they resulted in significantly more headaches!
- And my favorite demo


Comments from James’ readers
You can view the comments from JLW’s readers here.
Here’s the summary: None of them were persuaded that masks worked.
Analysis by a statistician of the 2 hour interview
Steve asked me to do a review of the video with timestamps and comments. Sorry it took so long to get this out, it was harder than I thought because Jason can’t stay on topic and there’s no good place to really point out things. I have some random timestamps below with thoughts, hopefully that’s kind of helpful. I hope my comments here don’t make me look too stupid on this thread of people much smarter than me. Maybe I should just “trust the experts” and not “think for myself” like Jason recommends. That’s obviously the right way to communicate science.
First – I really need to thank James for doing this! You clearly show that you know your stuff and can speak about it. You kept your cool with the yippiness and interrupting much better than I would have.
My big picture thoughts – The first half of the interview was Jason flip-flopping between being super precise to not look like he was p-hacking and then actually referring to sub-group analysis that was p-hacking. The second half was nitpicking about details of p-values when the analyses they did were so wrong, it’s really not worth worrying about.
Jason reminds me of the typical fast-talking know-it-all grad student who only succeeds because he can talk fast and sound technical. That probably is a bit because he’s not a real scientist – economics is so much squishier than physics, you can win by talking fast and using narrative rather than relying on clear experimental results. It all looks great to the non-expert observer and he’s puffed up by all the twitter love he’s gotten, so he looks extra confident. Unfortunately, all of the problems with his work are technical and will be over the head of most people.
Jason and weaseling about media portrayal of the story – James starts out asking Jason about what he thinks of the media overstating his conclusions. He tries to be honest and say that the media might have been a little too positive about it, but he won’t commit. Who wouldn’t? He’s getting all kinds of love from the media, especially the NYT and he’s been validated as a good liberal professor. The next hour of the conversation is Jason using technical terms to show that he followed the proper procedure “the preregistered, blah, blah blah”. Technically, he’s correct, the only thing they said they’d look for is the “effectiveness of masks” regardless of mask type or color. So when they say “masks work” they are correct, even though only surgical masks really worked and cloth were neutral (i.e., didn’t do anything). Of course if you look at this twitter thread he posted, he’s much more definite in his wording because he cares about the public narrative over the science.
He keeps coming back to the generic “masks work” because that’s the metric they said they’d report on. But of course the paper has many other analyses in it that suggest other benefits. That’s the whole “subgroup analysis” argument that kept coming up. The way the paper is written is reminiscent of p-hacking without p-hacking. That is, Jason says all masks work (because that’s the preregistered…) but then calls out specifics like surgical masks work really well. Or masks work better for old people. Or things like that. By mentioning them, he can tacitly build evidence that supports his position, but he still stays away from it technically. So it’s like a good lawyer coloring the jury but staying technically legal. He keeps conflating the idea of mask working with the idea of not being inconsistent with not working. Of course he never mentions the fact that purple masks perform much more differently than other masks. To me, the difference in performance of the same mask-type that differs only in color is a great way to see how much noise is in the system. He skips over that.
I don’t have much more to really say about the first hour. It was just Jason annoyingly repeating technical details but not really interpreting the science.
Then comes the imputation discussion. Others have covered that better, I’ll skip it. But it follows the same pattern, he says “we didn’t find much of an effect with cloth masks, but if we make up data it looks better. And then says, well we shouldn’t make up data.” It’s just another narrative where he tries to suggest data supports his opinion and then backs off to stay away from fraud.
The last hour really is really talking about all of the subgroup analyses they did. It’s basically p-hacking without p-hacking. For example, he’s adamant that “all masks work” because “surgical masks work and the data is not consistent with cloth masks not working”. And then if you factor in all of the age stratification and different types and colors of masks, there are lots of different subgroups they run to tacitly get significance. Then at the last minute he backs away to stay far enough away from a p-hacking fraud claim. It’s all pretty sneaky.
My biggest issue is just the bad analysis. For example, near 26:50 in the interview, he says that some of the villages had 20% mask-wearing compliance and others had 70% mask-wearing compliance. That likely doesn’t meet the homogeneity of variance needed for the stats they run. I also know from reading the mask/unmask counts are not balanced very well, so normal t- and p- tests don’t make sense. And the fact that they’re holding on to a p=0.03 when they have N=300,000 in the study just shows that they’re trying to find a signal in the noise. With that many people in the study, it should be clear if there’s an effect.
And of course none of my complaints about the analyses even matter when they use the wrong N. Ben Recht already pointed out that since this is cluster-randomized, it reduces the effective sample and completely washes out any difference. My complaint is that of the 300,000 people, they only tested about 10,000 for symptomatic seropositivity which means the variance for their t- and p- tests is much larger. Additionally, the effect size is on the order of 1 per 1,000 people (if I remember correctly), which is well within the false-positive rate of the seropositivity tests. They incorrectly use nigh-N variance to literally find a signal in the noise. I should actually plot a power curve for this, but haven’t gotten around to it. I’m sure it would not be flattening out and showing convergence.
Problems:
– mask compliance isn’t consistent between villages: no homogeneity of variance
– arms are unequal size for the simple p- tests
– cluster randomization reduces effective sample size
– they test 1/30th of the actual number of people in the study
– the effect size is on the order of the false-positive rate of the blood tests
Here are the raw notes we took while we were watching this. Maybe it will point others to make better comments. I’m notoriously bad at finding specifics, I’m much better at simply looking at the whole picture of the study and seeing that it’s bad.
4:30
says that masks are good in indoor places with poor ventilation
– that specific context was not addressed in the paper
near 8:00
in response to the Atlantic piece and a NY Times piece, he is very wishy-washy on whether all masks or just surgical/N95 masks are good – not making a commitment either way
primary preregistered specification ???
14:00
says that statistically insignificant (we never say that, we say not statistically significant or nonsignificant) doesn’t mean no effect
this argument carries less weight given the power of the study (600 villages and >300,000 people)
17:10
admits the study doesn’t have enough power to show an effect with cloth masks
18:15
weasel words about effectiveness and what’s reported in the media
23:50
they are acknowledging in the paper that masks work for many reasons, including selection bias, staying away from people who may be sick, etc., not specifically because of filtration by the masks
26:50
they admit they have many confounds and claim that they sort them out afterwards – this is not how it’s done
also says some villages had 20% wearing masks, some 70% wearing masks – sounds like a violation of homogeneity of variance assumption for the stats they use
30:20
he doesn’t communicate like a scientist – he argues like in debate club – he tries to talk the first and the fastest and doesn’t let the other person finish an argument, even when he’s agreeing with him – this reveals that he is an economist, not a scientist, because a curious scientist wants to hear the other person’s explanation and respond to it
39:30
admits that peer review doesn’t catch fraud
49:00
using weasel words that make me suspect p-hacking
52:00
discussion about imputation of data to increase power, which should not be necessary when you have >300,000 people – they’re trying to find a signal in noise
54:20
nitpicking about power curves
58:00
nitpicking about multiple inference tests
68:30
“hundreds” of subgroup analyses but only a few appeared in the paper – his response was “I don’t know that it was hundreds”
in other words, he was treating the subgroup analyses like targeted questions, which he insists they were not
69:30
he’s saying they’re choosing to report the data in a certain way because that’s what people are used to seeing (and therefore they didn’t do multiple inference corrections)
had he done it correctly, would the p-values have been too big and so people wouldn’t accept it and it wouldn’t have been published?
Postscript from James
James sent me this note today:
Check out this decision by the FDA on a drug for ALS.
Just like the Yale masking study,
Marginally significant p-value p = 0.03. Non-significant secondary outcomes.
The FDA panel said “not good enough.”
In short, if the outcome agrees with the narrative, it’s sufficient evidence to mandate it. But if you are being objective about the science (as in the ALS case), it’s insufficient.
Summary
Masks have never worked to stop a virus in history.
The laws of physics didn’t suddenly change when Tony Fauci suddenly changed his opinion on masking.
The Bangladesh study didn’t prove that masks work. The first author of the study failed to convince any knowledgeable statistician I know that the study showed masks work.
Flawed studies can make it look like masks work. But that doesn’t mean that they do.
This example shows just how critical it is for people who make claims to be open to defending their claims to challenge. This is how the world discovers truth.
All of us “misinformation spreaders” are open to being challenged by the CDC, NIH, FDA, public health officials, experts in epidemiology and infectious disease, and professors of medicine at any university in the US.
If UCSF’s Bob Wachter thinks the Bangladesh study is solid, perhaps he can defend it. Will he try? No. Not a chance.
I find it enormously troubling that not a single one of these “respected COVID authorities” are willing to challenge us on our views on masks or anything else. That is not how science is supposed to work. What are they so afraid of? Don’t they want to reveal the truth about who is right?
